
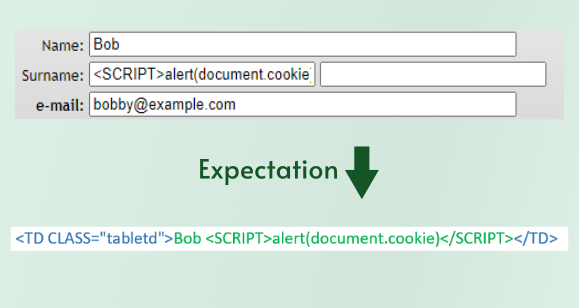
Let's take a simple example to ensure we all have a good understanding of how JavaScript injection works. Imagine a webpage where you can set your first name in your user profile. And let's suppose you chose you the name "Bob <SCRIPT>alert(document.cookie)</SCRIPT>". The first gap that allows an injection attack is the lack of input validation. The number of people whose name contains a "<" or a "(" is small enough (if greater than zero at all) that you don't want to base your business processes on them. If these characters are submitted to your website, not only should you block the save entirely, you probably want to log this as a security event and keep an eye on that user. But for our story, let's say this name was allowed.
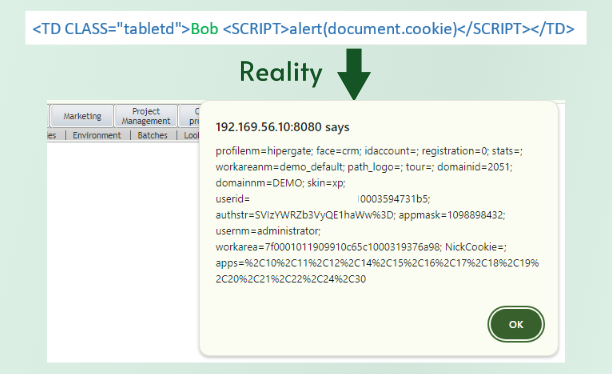 Next, let's say that our imaginary website displays a user's first name somewhere. Maybe there is a directory of users or maybe users can leave reviews and their first name is shown along side it. Traditionally, when the website is generating the page, it will pull the first name from the database, put it into some sort of template for the directory or review page, and then return the whole page to the user who requested it. This is where gap number two happens. If the website blindly places the value of the name into the webpage that is returned, the requester's browser has no way of knowing what was part of the template and what was data from the database, so it will render all of the HTML tags it receives the same. In this case, it will see the SCRIPT tag, assume the website meant for it to be there, execute the JavaScript inside the tag, and open an alert box containing the current user's cookies. An alert box isn't exactly a threat, but a real attacker would create JavaScript that would instruct the user's browser to transmit that cookie back to them, allowing them to collect the session cookie for every user who views a page with Bob's name in it.
Next, let's say that our imaginary website displays a user's first name somewhere. Maybe there is a directory of users or maybe users can leave reviews and their first name is shown along side it. Traditionally, when the website is generating the page, it will pull the first name from the database, put it into some sort of template for the directory or review page, and then return the whole page to the user who requested it. This is where gap number two happens. If the website blindly places the value of the name into the webpage that is returned, the requester's browser has no way of knowing what was part of the template and what was data from the database, so it will render all of the HTML tags it receives the same. In this case, it will see the SCRIPT tag, assume the website meant for it to be there, execute the JavaScript inside the tag, and open an alert box containing the current user's cookies. An alert box isn't exactly a threat, but a real attacker would create JavaScript that would instruct the user's browser to transmit that cookie back to them, allowing them to collect the session cookie for every user who views a page with Bob's name in it.
The best defense against injection attacks is output encoding. This means that when placing untrusted data into a template of some sort, the developer is aware of how that template is going to be read and converts any character that has special meaning in this use case to a harmless form of that character. For HTML, that starts with converting "<" and ">" characters in data into the HTML entities "<" and ">". If that were done in our example above, when the browser renders the page it received from the website, it would know to display a "<" after Bob's name instead of treating that character as the start of an HTML tag. There are some other ways of dealing with untrusted data, but those are specific to the context where they are used (e.g. parameterized queries usually have other ways of encoding data to prevent SQL injection).
So if every single input field is validated so that it cannot contain characters that lead to HTML/JavaScript execution or if every single place user controlled input is used by the website correctly encodes that data, then injection attacks will be completely blocked and you don't have to worry about the rest of the defenses in this article. However, experience shows that getting it right MOST of the time is pretty easy. Getting it right EVERY time is very hard. For that reason, browsers have built other defenses to protect session tokens.
HTTP Only Cookie Attribute
One of the first defenses against JavaScript-based attacks on session tokens was included in the first RFC defining the Set-Cookie header published in 2009. This is the "HttpOnly" attribute which can be applied to an individual cookie to prevent it from "revealing their contents via 'non-HTTP' APIs." The RFC specifically does not define what are considered HTTP and non-HTTP APIs, but the browser implementations (first by Internet Explorer 6 SP1 in 2002) have clearly defined JavaScript as a non-HTTP API. This means that when a webpage references "document.cookie" or a similar JavaScript call, cookies marked with the HttpOnly attribute will not be returned. Since JavaScript cannot access those cookies, JavaScript injected into a webpage cannot steal them.
So why not mark all cookies as HttpOnly? It almost never hurts. There are plenty of cookies where it wouldn't matter if an attacker read their value, but unless your application's client-side JavaScript specifically needs the value, marking a cookie as HttpOnly won't break anything. The browser will still send every cookie that's in-scope to your server. Based on testing many applications, there is a tendency for those that use a lot of client-side rendering for the user interface (e.g. sites that use Angular, React, etc.) to deliberately leave this attribute off, read the session token with the application, and then manually add it to API requests sent back to the server. This is not necessary and exposes the session token to attack by malicious JavaScript. Assuming that the server is using cookies for authentication (as opposed to an Authentication header) then an HttpOnly session cookie will still be sent with every request, even if it is initiated by JavaScript. So that API call would automatically have the session cookie with no action required from the developer.
Content Security Policies
The final defense to be covered here is Content Security Policies (CSPs) which are a mechanism that lets site developers specifically define which JavaScript should be executed based on where that JavaScript came from. CSPs can do more than just JavaScript defense, and we'll cover some of their other capabilities later, but for now let's focus on this use case.
CSPs were proposed in 2004 by Robert Hansen who is a prolific security researcher and, not coincidentally, the author of one of the definitive lists of methods to perform Cross-site Scripting. He observed that the root cause of JavaScript (and other) injection attacks was the difficulty a browser has in distinguishing between scripts that the site developer intended to be included in the web page from scripts that an attacker had managed to get added to the web page. He further observed that there are two very common methods of delivering JavaScript, within the page itself, and inside separate files that the page can reference. So the starting point of CSPs is the proposal that sites move ALL of their JavaScript code out of the page and into separate files, and then inform the browser that it should ignore any script code it finds inside the page. You may rightly observe that if an attacker can insert JavaScript code, they can also insert a reference to JavaScript code hosted on their own server, so CSPs also allow site developers to specify the specific domains that can host JavaScript for the page. With this kind of policy in place, an attacker would not only have to discover a way of injecting the script reference, but also a way to upload their own file into the domain that has been listed.
The introduction of the first W3C Candidate Recommendation on CSPs has some words of caution. "There is often a non-trivial amount of work required to apply CSP to an existing web application." This is true and is almost certainly the reason why CSPs are not more widely adopted. The protocol does contain a pathway that both eases the transition and provides ongoing visibility in the "report-to" directive. This gives the browser a URL where it will send information about any violations to the CSP that it encounters. An existing website trying to tune their CSP can use the "Content-Security-Policy-Report-Only" response header to communicate a policy to the browser, but not have the browser actually block anything. This way, the site owner can go through the violations reported and move the offending content or add the appropriate CSP entry until the site works without generating any "report-to" events. At that point the CSP can be set in enforcing mode (removing the "Report-Only" text from the header) and any further events that show up at the "report-to" URL can be considered as potential attacks.
There is one final item to consider when setting your CSP. Let's say you wanted to host all of your JavaScript libraries from an Amazon S3 bucket (or some other hosting provider/content delivery network), or maybe the author of a library you use has the file hosted there. You add "s3.amazonaws.com" to your CSP so that your site will be allowed to execute the scripts. You've just provided an attacker with a method of bypassing the CSP. This is because anyone can create their own s3 bucket and host their exploit script there. Amazon has some basic "know your customer" controls in place so this isn't exactly a free pass, but there are ways around those as well. So the pro-tip here is to consider each domain you put on your allow-list and think about how easy it would be for an attacker to get their own content on some service that falls inside that domain.
Conclusion
It's worth pointing out again that JavaScript Injection attacks can be used to accomplish a lot of different very bad things. Stealing a session token is a very common target, and is the reason we need to discuss the attacks here, but these defenses in particular need to be strong. Even if your session token is completely protected, if you allow an attacker to execute arbitrary JavaScript inside your user's browser, they are sure to be able to find something they can do that will ruin the user's day, and ultimately yours as well.
Other articles in this series
Part 1 - Overview
Part 2 - Network Sniffing
Part 3 - Token Exposure
Part 4 - JavaScript Injection (XSS) (this article)
Part 5 - Blind Session Abuse
Part 6 - Post-compromise Use
Bonus 1 - JWTs: Only Slightly Worse
Bonus 2 - Device Bound Session Tokens
Errata
See a mistake? Disagree with something?